Lenguaje independiente del contexto.
"Parser". Gobierna todo el proceso. Realiza el resto de la reducción al axioma de la gramática para comprobar que la instrucción en cuestión es correcta. Considera como símbolos terminales las unidades sintácticas devueltas por el analizador morfológico.
Dos tipos principales de análisis:
Que sea una gramática de tipo 2 (lenguaje independiente del contexto) no nos asegura que el autómata a pila sea determinista. Estos sólo representan un subconjunto de los lenguajes i.c.. A lo largo de las páginas siguientes iremos imponiendo diversas restricciones a las gramáticas. Las restricciones de un método no tienen porqué ser las mismas que las de otro (complementariedad).
Se parte del axioma y se va realizando la reducción. La palabra x (normalmente una instrucción) se llama meta u objetivo del análisis. La primera fase del análisis consiste en encontrar, entre las reglas cuya parte izquierda es el axioma, la que conduce a x.
Sea el axioma S y las reglas cuya parte izquierda es el axioma:
S ::= X1 X2 ... Xn | Y1 Y2 ... Ym | ...
Sea x la palabra a reconocer. El objetivo del análisis es encontrar una derivación tal que
S ->* x
Probaremos primero la regla
S ::= X1 X2 ... Xn
Debemos descomponer x en la forma
x = x1 x2 ... xny tratar de encontrar las derivaciones
X1 ->* x1
X2 ->* x2
...
Xn ->* xn
Cada una de las derivaciones anteriores es una submeta. Pueden ocurrir los siguientes casos:
Xi ::= Xi1 Xi2 ... Xin | Yi1 Yi2 ... Yim | ...elegimos la primera opción:
Xi ::= Xi1 Xi2 ... Xindescomponemos xi en la forma
xi = xi1 xi2 ... xinlo que nos da las nuevas submetas
Xi1 ->* xi1
Xi2 ->* xi2
...
Xin ->* xin
y continuamos recursivamente igual que antes.
Consiste en ordenar las distintas partes derechas de las reglas que comparten la misma parte izquierda de manera que la regla "buena" se analice antes.
Ejemplo:
E ::= T+E | T T ::= F*T | F F ::= i
Analizamos la cadena i*i. Probamos primero E::=T+E y obtenemos el árbol
E
-------|-------
T + E
-----
F * T
| |
i F
|
i
En cuanto comprobemos que el signo + no pertenece a la cadena objetivo, no es necesario volver a las fases precedentes del análisis tratando de obtener otra alternativa, sino que pasamos directamente a intentar E::=T.
E
|
T
-----
F * T
| |
i F
|
i
Una buena regla para ordenar la gramática es poner primero las partes derechas más largas. Si una parte derecha es la cadena vacía, debe ser la última. Si se llega a ella, automáticamente hay éxito en la submeta.
Ver "Teoría de Lenguajes, gramáticas y autómatas".
Son gramáticas en forma normal de Greibach en las que no existen dos reglas con la misma parte izquierda, cuya parte derecha empiece por el mismo símbolo terminal.
Conversión: si existen reglas de la forma:
U ::= aV | aW V ::= bX | cY W ::= dZ | eTtratamos de sustituir las dos reglas de parte izquierda U por
U ::= aK K ::= bX | cY | dZ | eTy aplicamos la misma sustitución a las nuevas reglas formadas.
La gramática se llama LL(1) de Knuth porque basta estudiar en cada momento un carácter de la cadena objetivo para saber qué regla se debe aplicar.
Se llama también "sin vuelta atrás" o "descenso recursivo". Se basa en poner la gramática en la forma normal de Greibach (LL(1)) y marchar directamente por el único camino permisible. Si en algún momento no se encuentra regla que aplicar, se puede generar directamente un mensaje de error.
Ejemplo: sea la gramática
E := T + E | T - E | T T := F * T | F / T | F F ::= i | (E)
En forma normal de Greibach queda:
E ::= iPTME | (ECPTME | iDTME | (ECDTME | iME | (ECME |
iPTSE | (ECPTSE | iDTSE | (ECDTSE | iSE | (ECSE |
iPT | (ECPT | iDT | (ECDT | i | (EC
T ::= iPT | (ECPT | iDT | (ECDT | i | (EC
F ::= i | (EC
M ::= +
S ::= -
P ::= *
D ::= /
C ::= )
En forma LL(1) queda:
E ::= iV | (ECV V ::= *TX | /TX | +E | -E | ^ X ::= +E | -E | ^ T ::= iU | (ECU U ::= *T | /T | ^ F ::= i | (EC C ::= )
Dada una gramática LL(1), formada por un conjunto de reglas de la forma
U ::= x X1 X2 ... Xn | y Y1 Y2 ... Ym | ... | z Z1 Z2 ... Zp
Generamos la siguiente función C:
int U (char *cadena, int i)
{
if (i<0) return i; /* Pasa errores anteriores */
switch (cadena[i]) {
case x:
i++;
i = X1 (cadena, i);
i = X2 (cadena, i);
. . .
i = Xn (cadena, i);
break;
case y:
i++;
i = Y1 (cadena, i);
i = Y2 (cadena, i);
. . .
i = Ym (cadena, i);
break;
...
case z:
i++;
i = Z1 (cadena, i);
i = Z2 (cadena, i);
. . .
i = Zp (cadena, i);
break;
/* Fin de cadena va a default */
default: return -n; /* Genera error n */
}
return i;
}
Si las reglas tienen la forma
U ::= x X1 X2 ... Xn | ... | z Z1 Z2 ... Zp | ^
Generamos la siguiente función C:
int U (char *cadena, int i)
{
if (i<0) return i; /* Pasa errores anteriores */
switch (cadena[i]) {
case x:
i++;
i = X1 (cadena, i);
i = X2 (cadena, i);
. . .
i = Xn (cadena, i);
break;
...
case z:
i++;
i = Z1 (cadena, i);
i = Z2 (cadena, i);
. . .
i = Zp (cadena, i);
break;
}
return i;
}
Ejemplo: la gramática anterior se reduce a:
int E (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case 'i':
i++;
i = V (cadena, i);
break;
case '(':
i++;
i = E (cadena, i);
i = C (cadena, i);
i = V (cadena, i);
break;
default: return -1;
}
return i;
}
int V (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case '*':
case '/':
i++;
i = T (cadena, i);
i = X (cadena, i);
break;
case '+':
case '-':
i++;
i = E (cadena, i);
break;
}
return i;
}
int X (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case '+':
case '-':
i++;
i = E (cadena, i);
break;
}
return i;
}
int T (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case 'i':
i++;
i = U (cadena, i);
break;
case '(':
i++;
i = E (cadena, i);
i = C (cadena, i);
i = U (cadena, i);
break;
default: return -2;
}
return i;
}
int U (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case '*':
case '/':
i++;
i = T (cadena, i);
break;
}
return i;
}
int F (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case 'i':
i++;
break;
case '(':
i++;
i = E (cadena, i);
i = C (cadena, i);
break;
default: return -3;
}
return i;
}
int C (char *cadena, int i)
{
if (i<0) return i;
switch (cadena[i]) {
case ')':
i++;
break;
default: return -4;
}
return i;
}
La cadena x se analiza invocando
axioma (x, 0);
En nuestro ejemplo:
E (x, 0);
Si devuelve strlen(x), la cadena x es correcta. En caso contrario, devolverá un número negativo que indica el error detectado.
Ejemplo: análisis de "i+i*i".
E ("i+i*i", 0) = V ("i+i*i", 1) =
= E ("i+i*i", 2) =
= V ("i+i*i", 3) =
= X ("i+i*i", T ("i+i*i", 4)) =
= X ("i+i*i", U ("i+i*i", 5)) =
= X ("i+i*i", 5) =
= 5
Ejemplo: análisis de "i+i*".
E ("i+i*", 0) = V ("i+i*", 1) =
= E ("i+i*", 2) =
= V ("i+i*", 3) =
= X ("i+i*", T ("i+i*", 4)) =
= -2
Parte del objetivo y trata de reconstruir las producciones para llegar a reducir al axioma.
Ejemplo: sea la gramática
E ::= E + T | E - T | T T ::= T * F | T / F | F F ::= i | (E)y la expresión (reducida por el analizador morfológico) i+i*i.
Colocamos un puntero sobre la cadena a analizar.
meta: E i + i * i ^
La única regla que empieza por "i" es F::=i. La aplicamos:
meta: E F | i + i * i ^
La cadena a obtener (subobjetivo), vista desde arriba, es F+i*i. La única regla aplicable (que empiece por F) es T::=F. La aplicamos:
meta: E T | F | i + i * i ^
La cadena a obtener (subobjetivo), vista desde arriba, es T+i*i. Hay dos reglas cuya parte derecha empieza por T, E::=T y T::=T*F. Probamos la de parte derecha más larga (la segunda): regla aplicable (que empiece por F) es T::=F. La aplicamos:
meta: E
T
|----
T * F
|
F
|
i + i * i
^
y avanzamos el puntero para comprobar. La submeta a encontrar es *F y la
subcadena a generar es +i*i. Como comienzan por distinto símbolo terminal, no
es posible hacerlo. Retrocedemos a la situación anterior y aplicamos la otra
regla, E::=T.
meta: E E | T | F | i + i * i ^
El objetivo actual es E+i*i. Ha aparecido el axioma, pero queda cadena por reducir. Sólo hay una regla cuya parte derecha empiece por E, E::=E+T. La aplicamos:
meta: E
E
|----
E + T
|
T
|
F
|
i + i * i
^
Ahora tenemos el subobjetivo +T que debe producir +i*i. Los dos símbolos terminales iniciales coinciden. Los identificamos y avanzamos el puntero.
meta: E
E
|----
E | T
| | Submeta: T
T |
| |
F |
| |
i + i * i
^
Partiendo de i*i hay que comprobar la submeta T. La única regla que empieza por "i" es F::=i. La aplicamos:
meta: E
E
|----
E | T
| | Submeta: T
T |
| |
F | F
| | |
i + i * i
^
La única regla que empieza por F es T::=F. La aplicamos:
meta: E
E
|----
E | T
| | Submeta: T
T | T
| | |
F | F
| | |
i + i * i
^
Hemos encontrado la submeta T. Pero aún queda cadena. Miramos si hay alguna regla cuya parte derecha empiece por T. Hay dos, E::=T y T::=T*F. Probamos la de parte derecha más larga (la segunda).
meta: E
E
|----
E | T
| | Submeta: T
| | T
| | |----
T | T * F
| | |
F | F
| | |
i + i * i
^
Avanzamos el puntero y comprobamos la subcadena *F con la subcadena *i. Los dos símbolos terminales iniciales coinciden. Los identificamos y avanzamos:
meta: E
E
|----
E | T
| | Submeta: T
| | T
| | |----
T | T | F
| | | | submeta: F
F | F |
| | | |
i + i * i
^
Partiendo de i hay que comprobar la submeta F. La única regla que empieza por "i" es F::=i. La aplicamos:
meta: E
E
|----
E | T
| | Submeta: T
| | T
| | |----
T | T | F
| | | | Submeta: F
F | F | F
| | | | |
i + i * i
^
Todas las metas y submetas coinciden. Luego ésta es la reducción al axioma buscada. El árbol de análisis queda:
E |---- E | T | | |---- T | T | F | | | | | F | F | | | | | | | i + i * i
Introducir aquí la teoría de formas sentenciales, frases y asideros, y la de relaciones.
Dada una gramática limpia G de axioma Z, definimos las siguientes relaciones de precedencia entre los símbolos del vocabulario A = AN U AT. Para todo R,S en A:
R =. S <=> existe U::=uRSv en P
R <. S <=> existe U::=uRTv en P,
tal que T F+ S en P.
R >. S <=> existe U::=uTWv en P,
tal que T L+ R, W F* S en P.
R <.= S <=> R <. S ó R =. S
R >.= S <=> R >. S ó R =. S
Teorema: R =. S <=> RS aparece en el asidero de alguna forma sentencial.
Prueba:
RS es parte de un asidero. Por definición de asidero existe una regla U::=uRSy => R =. S, q.e.d.
Teorema: R >. S <=> existe una forma sentencial uRSv donde R es el símbolo final de un asidero.
Prueba:
R es la cola de un asidero y va seguido por S. Reducimos hasta que S esté en el asidero. Esto da un árbol para la forma sentencial xTSy, donde T ->* tR.
Teorema: R <. S <=> existe una forma sentencial uRSv donde S es la cabeza de un asidero.
Se demuestra de forma análoga.
Definición: G es una G.P.S. o G.P.(1,1) si:
Se llama G.P.(1,1) porque sólo se usa un símbolo a cada lado de un posible asidero para decidir si lo es o no.
Problema: si no se cumple esto, se puede manipular la gramática para intentar que se cumpla. La recursividad a izquierdas o a derechas da problemas (salen dos relaciones de precedencia con los símbolos que van antes o después del recursivo). Para evitarlo, se puede estratificar la gramática, añadiendo símbolos nuevos, pero si hay muchas reglas es muy pesado.
Supondremos que toda forma sentencial queda rodeada por dos símbolos especiales de principio y fin de cadena: |- -|, que no están en A y tales que, para todo S en A, |- <. S y S >. -|.
Teorema: Una gramática de precedencia simple no es ambigua. Además, el asidero de una forma sentencial S1 ... Sn es la subcadena Si ... Sj, situada más a la izquierda tal que:
Si-1 <. Si =. Si+1 =. ... =. Sj-1 =. Sj >. Sj+1
Prueba:
Si no es asidero, cada uno de los símbolos de Si-1 Si ... Sj Sj+1 debe aparecer más pronto o más tarde como parte de un asidero. Sea St el primero que aparece.
Como el asidero es único (por construcción) y sólo puede ser parte derecha de una regla (por ser G.P.S.) sólo se puede aplicar una regla para reducir. Luego la gramática no es ambigua.
<. = (=.) +.x (F+)donde +.x es el producto booleano de matrices. (Por definición del producto de relaciones y la definición de <. y =.).
>. = (L+)' +.x (=.) +.x (F*)donde ' es la transposición de matrices. La demostración queda como ejercicio.
MP(i,j) = 0 si no existe relación entre Si y Sj
= 1 si Si <. Sj
= 2 si Si =. Sj
= 3 si Si >. Sj
Ejemplo:
S ::= aSb | c
Matrices de las relaciones:
=. : 0 0 1 0 F : 0 1 0 1 L : 0 0 1 1
1 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0
F+ = F
L+ = L
F* : 1 1 0 1
0 1 0 0
0 0 1 0
0 0 0 1
Operando, sale:
<. : 0 0 0 0 >. : 0 0 0 0
0 1 0 1 0 0 0 0
0 0 0 0 0 0 1 0
0 0 0 0 0 0 1 0
Con lo que la matriz de precedencia queda:
S a b c -|
----------
S | = >
a |= < < >
b | > >
c | > >
|-|< < < <
Analicemos la instrucción: aacbb
Pila Entrada
------------ ------------
|- < aacbb-|
|-<a < acbb-|
|-<a<a < cbb-|
|-<a<a<c > bb-|
|-<a<a=S = bb-|
|-<a<a=S=b > b-|
|-<a=S = b-|
|-<a=S=b > -|
|-<S -|
Luego la cadena es aceptada.
Analicemos la instrucción: aabb
Pila Entrada
------------ ------------
|- < aabb-|
|-<a < abb-|
|-<a<a bb-| (no hay relación)
Luego la cadena es rechazada.
Analicemos la instrucción: acbb
Pila Entrada
------------ ------------
|- < acbb-|
|-<a < cbb-|
|-<a<c > bb-|
|-<a=S = bb-|
|-<a=S=b > b-|
|-<S = b-|
|-<S=b > -| (no hay regla)
Luego la cadena es rechazada.
La matriz de precedencias ocupa NxN. A veces se puede construir dos funciones de precedencia que ocupan sólo 2xN. (Linealización de la matriz). Estas funciones, de existir, no son únicas (hay infinitas).
Para el ejemplo anterior valen:
|- S a b c -|
f 0 2 2 3 3
g 2 3 2 3 0
Si se pueden construir f y g, se verifica que
Existen matrices no linearizables. Ejemplo:
A B
A = >
B = =
pues debería ser
f(A) = g(A) f(A) > g(B) f(B) = g(A) f(B) = g(B)
Es decir:
f(A) > g(B) = f(B) = g(A) = f(A) => f(A) > f(A)
¡Contradicción!
Construcción de las funciones, cuando no hay inconsistencias:
Prueba:
Si f(Si)=g(Sj), existe un camino cerrado fi-gj-fk-gl-...-gm-fi, lo que implica que Si>.Sj, Sk<.=Sj, Sk>.=Sl, ... Si<.=Sm y reordenando: Si>.Sj>.=Sk>.=Sl>.=...>.=Sm>.=Si, es decir: f(Si)>f(Si), ¡contradicción!.
Ejemplo: grafo para obtener las funciones de precedencia del ejemplo anterior:
fS <-- --> gS
| |
fa <-|-|-- ga
^<--| |
|---|--|
||----->
fb -|----> gb
| ^
-|------|
fc ||----- gc
Mecanización del cálculo anterior: un grafo equivale a la matriz booleana de la relación xRy<=>hay un arco del nodo x al nodo y. Representamos el grafo por la matriz B 2Nx2N:
(0) (>.=)
(<.=)' (0)
Construimos B*. f(Si)=número de unos en la fila i. g(Si)=número de unos en la fila N+i.
En el ejemplo, B es la matriz
0 0 0 0 0 0 1 0
0 0 0 0 1 0 0 0
0 0 0 0 0 0 1 0
0 0 0 0 0 0 1 0
0 1 0 0 0 0 0 0
0 1 0 0 0 0 0 0
1 0 0 0 0 0 0 0
0 1 0 0 0 0 0 0
B* es la matriz
1 0 0 0 0 0 1 0
0 1 0 0 1 0 0 0
1 0 1 0 0 0 1 0
1 0 0 1 0 0 1 0
0 1 0 0 1 0 0 0
0 1 0 0 1 1 0 0
1 0 0 0 0 0 1 0
0 1 0 0 1 0 0 1
y las dos funciones f, g, salen como se dijo antes. Basta añadir los
símbolos de principio y fin de cadena (con valor 0).
El uso de las funciones supone pérdida de información. Por ejemplo:
Pila Entrada
------------ ------------
|- < aabb-|
|-<a < abb-|
|-<a<a = bb-|
|-<a<a=b > b-| (no hay regla)
Ha habido que hacer un paso más.
Tienen la siguiente restricción: en su conjunto de producciones no existe una regla de la forma:
U ::= xVWydonde V,W en AN. En estas gramáticas, los símbolos terminales se llaman operadores, los no terminales operandos.
Dada una gramática limpia de operadores, definimos las siguientes relaciones de precedencia entre los operadores: Para todo R,S en AT:
R =. S <=> existe U::=uRSv en P
o existe U::=uRVSv en P, V en AN.
R <. S <=> existe U::=uRTv en P, T en AN,
tal que T =>+ Sx
o T =>+ VSx, V en AN.
R >. S <=> existe U::=uTSv en P, T en AN,
tal que T =>+ xR
o T =>+ xRV, V en AN.
R <.= S <=> R <. S ó R =. S
R >.= S <=> R >. S ó R =. S
Definición: G es una G.P.O. si:
U FO S <=> U::=Sx ó U::=VSx en P, U,V en AN, S en AT.
U LO S <=> U::=xS ó U::=xSV en P, U,V en AN, S en AT.
Las dos relaciones anteriores se definen como matrices del mismo tamaño que las relaciones F y L, ya conocidas.
<. = (=.S) +.x (F*) +.x (FO)donde +.x es el producto booleano de matrices y =.S es la relación =., tal como se definió para las gramáticas de precedencia simple.
>. = ((L*) +.x (LO))' +.x (=.S)donde ' es la transposición de matrices.
El equivalente del asidero se llama frase primaria. Es una frase que contiene al menos un símbolo terminal, pero no una frase menor que ella. Un teorema nos asegura que para toda frase primaria Si...Sj se cumple que
Si-1 <. Si =. Si+1 =. ... =. Sj-1 =. Sj >. Sj+1
Para reducir hacia el axioma tomamos la frase primaria situada más a la izquierda en la forma sentencial.
Ejemplo:
E ::= E+T | T T ::= T*F | F F ::= (E) | i | -F
La matriz de relaciones es:
+ * ( ) -
+ > < < > <
* > > < > <
( < < < = <
) > > >
- > > < > <
El algoritmo es como el de las gramáticas de precedencia simple, pero se ignoran los símbolos no terminales.
Vamos a ver un algoritmo reducido que se emplea para el análisis y el cálculo de expresiones:
El algoritmo utiliza dos pilas: una de operadores, otra de operandos. La ventaja principal de estas gramáticas es que la matriz de las relaciones es mucho más pequeña.
MP(i,j) = 0 si no existe relación entre Si y Sj
= 1 si Si <. Sj
= 2 si Si =. Sj
= 3 si Si >. Sj
Ejemplo: análisis de a*(b+c).
a*(b+c)-|
||- |
< *(b+c)-|
||- a-|
< (b+c)-|
||-* a-|
b+c)-|
||-*( a-|
< +c)-|
||-*( ba-|
c)-|
||-*(+ ba-|
> )-|
||-*(+ cba-|
)-|
||-*( Pa-| P=b+c
> -|
||-* Pa-|
-|
||- Q-| Q=a*P
Este algoritmo tiene problemas, como no localizar los errores en instrucciones como "a b +", "+b-c", etc. Se puede añadir una prueba para comprobar que no hay dos operandos seguidos, ni un operando seguido por función monádica, o se puede pasar a un algoritmo semejante al de las gramáticas de precedencia simple.
Informalmente, una gramática LR(k) (Knuth, 1965) permite analizar de forma determinista, de izquierda a derecha, una cadena de entrada, observando a lo sumo los siguientes elementos:
Los analizadores basados en gramáticas LR(k) presentan características comunes con los analizadores "top-down" y "bottom-up".
Es una producción con un marcador, que indica hasta donde hemos llegado en el análisis de la parte derecha. Por ejemplo, sea la gramática parcial
1: <Bloque> ::= begin <Decs> ; <Ejecs> end 2: <Decs> ::= <Dec> 3: | <Decs> ; <Dec> 4: <Ejecs> ::= <Ejec> 5: | <Ejec> ; <Ejecs>
Son configuraciones válidas las siguientes:
(1,0)
(2,1)
(3,3)
donde (a,b) indica que estamos analizando la posición b (en origen 0) de
la parte derecha de la regla de producción número a.
Se representa mediante un conjunto de configuraciones. Indica las configuraciones posibles en la situación actual del análisis. Su número es finito.
Supongamos que estamos en la configuración representada por (a,b), y que el símbolo siguiente a la posición b en la parte derecha de la regla a es el símbolo no terminal U. Sean c,...,d las reglas cuya parte izquierda es U. Entonces, de la configuración (a,b) se podrá pasar a las configuraciones (c,0),...,(d,0). Si aplicamos el mismo procedimiento indefinidamente, hasta que no aparezcan configuraciones nuevas, tendremos la "clausura" de la configuración (a,b): el conjunto de estados que han ido apareciendo, incluido el (a,b). Si partimos de un conjunto de configuraciones (un estado), la clausura correspondiente será igual a la unión de las clausuras de las configuraciones del estado.
Para preparar el análisis LR(k) de una gramática hacemos inicialmente dos cosas:
S' ::= S -|
donde S' es un símbolo no terminal nuevo (nuevo axioma), S es el axioma de
la gramática original, y -| es un símbolo terminal nuevo (símbolo final de
cadena) que, además, añadimos al final de la cadena de entrada. Esta regla
pasa a ser la regla número 0 de la nueva gramática. Las demás reglas quedan
como estaban.
Dado un estado, se puede pasar al estado sucesor mediante la operación "corrimiento", que consiste en avanzar un símbolo sobre la cadena de entrada, pasando además del estado actual a otro nuevo, que se obtiene así:
Obsérvese que en la cadena de entrada podemos encontrar símbolos terminales o no terminales, como veremos a continuación.
Cuando una configuración representa el final de la parte derecha de una regla, se puede aplicar esa regla, añadiendo su parte izquierda a la izquierda de la cadena de entrada, eliminando de la lista de estados por los que se ha pasado los que corresponden a la parte derecha de la regla aplicada, y volviendo al estado anterior al comienzo del análisis de dicha regla.
La tabla del análisis tiene tantas filas como estados accesibles a partir del inicial, y tantas columnas como símbolos del vocabulario.
Para construir la tabla del análisis, partimos del estado inicial y calculamos los estados accesibles a partir de él, los estados accesibles a partir de éstos, etc., hasta que no salgan estado nuevos, utilizando únicamente la operación corrimiento. A continuación, rellenamos algunas casillas con la operación reducción, utilizando para ello una regla que veremos después.
Además, pondremos "Fin" en la casilla cuya fila es el estado inicial y cuya columna es el axioma. Esto sólo podremos hacerlo en algunas gramáticas, en aquéllas en las que el axioma no puede aparecer en ninguna forma sentencial. Más adelante veremos cómo se actúa cuando esto no es cierto.
Sea el ejemplo de la gramática que hemos visto antes. Consideraremos terminales a los símbolos <Dec> y <Ejec>.
Nuestra tabla inicial es:
Bloque Decs Ejecs Dec Ejec begin ; end -|
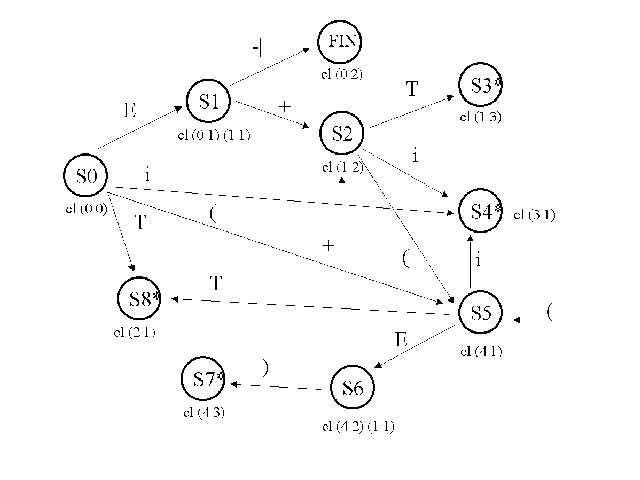
S0 Fin
donde S0=clausura {(0,0)} = {(0,0),(1,0)}.
En el estado inicial, ignoraremos la configuración (0,0), cuya casilla ya está rellena. La otra, (1,0), es anterior a un símbolo terminal: "begin". Luego el único estado accesible desde el inicial es la clausura de {(1,1)} = {(1,1),(2,0),(3,0)} = S1. La tabla queda:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1
A partir de S1 podemos encontrar en la cadena de entrada los símbolos <Dec> y <Decs>. <Dec> nos pasa a la configuración (2,1), <Decs> a la {(1,2),(3,1)}. Tendremos, pues, los estados S2=clausura {(2,1)}={(2,1)} y S3=clausura {(1,2),(3,1)}={(1,2),(3,1)}. La tabla queda:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2
S3
Desde S2 ya no se puede seguir: es fin de regla. Desde S3 sí. En ambos casos, el símbolo siguiente sólo puede ser ";". Las configuraciones siguientes son: {(1,3),(3,2)}. El estado siguiente será su clausura: S4={(1,3),(3,2),(4,0),(5,0)}. La tabla queda:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2
S3 S4
S4
Partiendo de S4, podemos encontrar los símbolos <Ejecs>, <Dec> y <Ejec>. Tendremos, por tanto, tres transiciones posibles. La primera nos lleva a {(1,4)}, cuya clausura es él mismo. Lo llamaremos S5. La segunda nos lleva a {(3,3)}, cuya clausura es él mismo. Lo llamaremos S6. La tercera nos lleva a {(4,1),(5,1)}, cuya clausura es él mismo. Lo llamaremos S7. La tabla queda:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2
S3 S4
S4 S5 S6 S7
S5
S6
S7
Desde S5 sólo podemos encontrar el símbolo "end", que nos lleva a {(1,5)}, cuya clausura es él mismo. Lo llamamos S8. Desde S6 no podemos llegar a ningún sitio: es fin de regla. Desde S7 podemos encontar el símbolo ";" y llegar a {(5,2)}, cuya clausura es {(5,2),(4,0),(5,0)}, un estado nuevo. Lo llamamos S9. La tabla queda:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2
S3 S4
S4 S5 S6 S7
S5 S8
S6
S7 S9
S8
S9
Desde S8 no podemos seguir: es fin de regla. Desde S9 podemos encontrar <Ejecs> o <Ejec>. El primero nos lleva a {(5,3)}, cuya clausura es él mismo. Lo llamamos S10. El segundo nos lleva a {(4,1),(5,1)}, es decir, a S7. La tabla queda:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2
S3 S4
S4 S5 S6 S7
S5 S8
S6
S7 S9
S8
S9 S10 S7
S10
Desde S10 no podemos seguir: es fin de regla. Por tanto, ya no hay más estados. La tabla está completa, salvo por la operación reducción.
Resumiendo: los estados encontrados son:
S0 {(0,0),(1,0)}
S1 {(1,1),(2,0),(3,0)}
*S2 {(2,1)}
S3 {(1,2),(3,1)}
S4 {(1,3),(3,2),(4,0),(5,0)}
S5 {(1,4)}
*S6 {(3,3)}
*S7 {(4,1),(5,1)}
*S8 {(1,5)}
S9 {(5,2),(4,0),(5,0)}
*S10 {(5,3)}
donde los estados que contienen una configuración final de regla aparecen
señalados con un asterisco.
Dependiendo de la regla utilizada para rellenar algunas casillas de la tabla con la operación reducción, tendremos distintos tipos de familias de analizadores LR(k).
La regla es: "si un estado contiene configuraciones de final de regla, reduciremos esa regla en todas las casillas correspondentes a un símbolo terminal".
La aplicación de la regla anterior puede provocar conflictos de dos tipos:
La aplicación de esta regla al ejemplo anterior nos daría la siguiente tabla:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2 R2 R2 R2 R2 R2 R2
S3 S4
S4 S5 S6 S7
S5 S8
S6 R3 R3 R3 R3 R3 R3
S7 R4 R4 R4 R4/S9 R4 R4
S8 R1 R1 R1 R1 R1 R1
S9 S10 S7
S10 R5 R5 R5 R5 R5 R5
Tenemos, pues un conflicto corrimiento-reducción. Por tanto, esta gramática no es LR(0).
Si al aplicar la regla anterior no hay ningún conflicto, decimos que la gramática está en forma LR(0). Por ejemplo, sea la gramática:
1: E ::= E + T 2: E ::= T 3: T ::= i 4: T ::= ( E )
Añadimos la regla 0:
0: S ::= E -|
Aplicando la técnica anterior, obtenemos la siguiente tabla de análisis:
E T i + ( ) -|
S0 S1 S8 S4 S5
S1 S2 Fin
S2 S3 S4 S5
S3 R1 R1 R1 R1 R1
S4 R3 R3 R3 R3 R3
S5 S6 S8 S4 S5
S6 S2 S7
S7 R4 R4 R4 R4 R4
S8 R2 R2 R2 R2 R2
Obsérvese que, en este caso, el axioma sí puede aparecer como parte de una forma sentencial, por lo que hemos tenido que introducir un estado más (S1), tratando la configuración (0,0) como otra cualquiera. La situación de aceptación, señalada por Fin, tiene lugar en la configuración (0,1), que aparece en dicho estado nuevo cuando se localiza el símbolo de fin de cadena.
Esta gramática deja de ser LR(0) si se introduce la precedencia de operadores. También surgen conflictos si existen reglas que generan la cadena vacía, especialmente cuando hay otras reglas con la misma parte izquierda.
La regla es: "si un estado contiene configuraciones de final de regla, reduciremos esa regla en todas las casillas correspondentes a un símbolo terminal que aparezca detrás de la parte izquierda de esa regla (directamente o después de alguna derivación) en la parte derecha de otra".
La aplicación de esta regla al ejemplo anterior nos daría la siguiente tabla:
Bloque Decs Ejecs Dec Ejec begin ; end -|
S0 Fin S1
S1 S3 S2
S2 R2
S3 S4
S4 S5 S6 S7
S5 S8
S6 R3
S7 S9 R4
S8 R1
S9 S10 S7
S10 R5
Si al aplicar la regla anterior no hay ningún conflicto, decimos que la gramática está en forma SLR(1). Para cualquier lenguaje independiente del contexto determinista existe una gramática SLR(1) que lo representa.
En las gramáticas LR(1), cada configuración se incrementa con información sobre los símbolos de entrada que pueden venir a continuación. Esto complica los estados y las transiciones, pero en general no es necesario. Se demuestra que todo lenguaje representable mediante una gramática LR(1) también puede representarse mediante una gramática SLR(1).
Independientes del contexto (Chomsky-tipo 2)
|
Ind. contexto deterministas = SLR(1) = LR(1)
-------------------------------------
LL(k) Precedencia simple
| |
LL(1) Precedencia operadores
Para realizar el análisis, aplicaremos el siguiente algoritmo:
Utilizaremos la tabla y la gramática de nuestro ejemplo para analizar la cadena de entrada:
begin <Dec> ; <Dec> ; <Ejec> ; <Ejec> end
Partimos del estado inicial S0 = {(0,0),(1,0)}. La sucesión de estados por los que pasamos es:
Estados Cadena de entrada Acción ------- -------------------------------------------- ------ S0 begin <Dec> ; <Dec> ; <Ejec> ; <Ejec> end -| S1 S1 <Dec> ; <Dec> ; <Ejec> ; <Ejec> end -| S2 S0 S2 ; <Dec> ; <Ejec> ; <Ejec> end -| R2 S1 S0 S1 <Decs> ; <Dec> ; <Ejec> ; <Ejec> end -| S3 S0 S3 ; <Dec> ; <Ejec> ; <Ejec> end -| S4 S1 S0 S4 <Dec> ; <Ejec> ; <Ejec> end -| S6 S3 S1 S0 S6 ; <Ejec> ; <Ejec> end -| R3 S4 S3 S1 S0 S1 <Decs> ; <Ejec> ; <Ejec> end -| S3 S0 S3 ; <Ejec> ; <Ejec> end -| S4 S1 S0 S4 <Ejec> ; <Ejec> end -| S7 S3 S1 S0 S7 ; <Ejec> end -| S9 S4 S3 S1 S0 S9 <Ejec> end -| S7 S7 S4 S3 S1 S0 S7 end -| R4 S9 S7 S4 S3 S1 S0 S9 <Ejecs> end -| S10 S7 S4 S3 S1 S0 S10 end -| R5 S9 S7 S4 S3 S1 S0 S4 <Ejecs> end -| S5 S3 S1 S0 S5 end -| S8 S4 S3 S1 S0 S8 -| R1 S5 S4 S3 S1 S0 S0 <Bloque> -| Fin